
Dynamic hashing is a flexible method used in computer science to manage data efficiently within a hash table. This technique permits the hash table's size to adapt dynamically based on changing data volumes. Initially, a fixed-size hash table is employed, adjusting its capacity as more elements are added or removed.
Database systems often employ dynamic hashing to handle evolving data quantities. For instance, in a database storing customer records, dynamic hashing automatically accommodates new customers by creating additional data buckets for their records. Conversely, when customers are removed, corresponding data buckets are also eliminated automatically.
Two primary types of dynamic hashing include:
- Extendible hashing: This technique manages the hash table's size by utilizing a hierarchy of hash tables, each a subset of the next larger one. When inserting a new element, it starts by placing it into the smallest hash table capable of holding it. If that table is full, a larger one is created, and the element is inserted there. This process continues until a non-full hash table is found.
- Chained hashing: Here, elements are stored in linked lists associated with their hash values. New elements are appended to these lists based on their hash values. If a linked list becomes excessively long, the hash table is resized, and elements are redistributed among new hash tables.
These dynamic hashing techniques offer scalability and adaptability, ensuring efficient data management in changing scenarios within hash tables.
Both extendible hashing and chained hashing are efficient ways to implement dynamic hashing. However, extendible hashing is more efficient for small to medium-sized hash tables, while chained hashing is more efficient for large hash tables.
Dynamic hashing offers several advantages in managing data efficiently within a database:
- Variable-Sized Data Handling: One of its primary advantages is its capability to manage variable-sized data items effectively. Unlike static hashing, which may struggle with fixed bucket sizes, dynamic hashing adapts well to varying data sizes, accommodating them without complications.
- Efficient Insertion and Deletion Operations: Dynamic hashing excels in performing insertion and deletion operations efficiently. It dynamically adjusts the structure as data items are added or removed, preventing significant overhead and maintaining performance.
- Reduced Likelihood of Collisions: Compared to static hashing, dynamic hashing is less prone to collisions. Its adaptive nature ensures that buckets are adjusted dynamically, reducing the probability of multiple data items hashing to the same location.
However, dynamic hashing also has its drawbacks:
- Complex Implementation: Implementing dynamic hashing can be more intricate compared to static hashing techniques. It involves managing split and merge operations of buckets dynamically, which requires a deeper understanding of algorithms and data structures.
- Higher Memory Requirements: Dynamic hashing may demand more memory resources than static hashing. The dynamic adjustments and management of bucket sizes could potentially result in increased memory overhead, especially in scenarios where the data distribution is uneven.
- Efficiency Challenges with Large Hash Tables: While dynamic hashing performs well with smaller or moderate-sized hash tables, it might encounter efficiency issues with extremely large hash tables. The overhead of managing dynamic changes in the table structure could impact performance negatively in these scenarios.
Understanding the advantages and disadvantages of dynamic hashing helps in making informed decisions when choosing hashing techniques for specific database applications.
Extendible hashing
Creating the Initial Directory in Extendible Hashing
Let's illustrate the process of creating the initial directory for an extendible hash table that can hold up to three elements (hash table of size 3) per bucket, using the given elements: 10, 22, 9, 4, 20, 7, 16, and 28.
- Creating the Initial Directory

- Inserting 10 (hash value: 01010): The hash function assigns 10 to bucket address 0. As the bucket at address 0 is empty, 10 is inserted into this bucket.

- Inserting 22 (hash value: 10110): The hash function assigns 22 to bucket address 10. As the bucket at address 10 is empty, 22 is inserted here.

- Inserting 9 (hash value: 01001): The hash function assigns 9 to bucket address 1. As the bucket at address 1 is empty, 9 is inserted into this bucket.
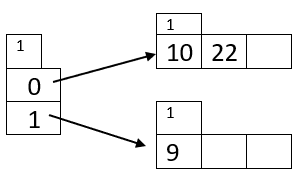
- Inserting 4 (hash value: 00100): The hash function assigns 4 to bucket address 0. As the bucket at address 0 is empty, 4 is inserted into this bucket.

- When attempting to insert the element 20, the hash function assigns it to bucket address 0 (hash (20) = 10100). Upon verification, it's observed that adding item 20 to the "0" bucket leads to an overflow situation. This occurrence fulfills the initial condition where the global depth equals the bucket depth.

- The action taken to resolve the overflow involves several steps. First, the overflowing bucket is split, prompting the directories to expand, and both the global depth and bucket depths are incremented. Subsequently, the items present in the overflowing bucket undergo rehashing after the split. With the increment by 1 in the global depth, it now stands at 2. Consequently, the rehashing process applies to elements 10, 22, 4, and 20.

- Inserting 7 (hash value: 00100): The hash function assigns 7 to bucket address 00. As the bucket at address 00 is empty, 7 is inserted into this bucket.

- Inserting 16 (hash value: 10000): The hash function assigns 16 to bucket address 00. As the bucket at address 00 is empty, 16 is inserted into this bucket.

- Inserting 28 (hash value: 11100): The hash function assigns 28 to bucket address 00. However, upon adding item 28 to the "00" bucket, it causes an overflow situation. This occurrence satisfies the condition where the global depth is equivalent to the bucket depth. The global depth increases to 3, and rehashing redistributes elements across the updated buckets.

- Split the bucket, grow directories, increment the global and bucket depths. Also, rehashing of items present in the overflowing bucket takes place after the split. And, since the global depth is incremented by 1, now, the global depth will be 3. Hence, 4,20,16,28 are now rehashed.

- Inserting 5 (hash value: 00101): The hash function assigns 5 to bucket address 01. As the bucket at address 01 is empty, 5 is inserted here.

Chained hashing
Chained hashing, also known as separate chaining, is a dynamic hashing technique used to manage hash tables. In this method, the hash table can grow or shrink based on the number of elements it needs to accommodate.
Basic Operations:
- Insertion: When adding a new element to the hash table, it gets appended to a linked list associated with its hash value.
- Handling Long Lists: If a linked list associated with a slot becomes too long, it triggers a resizing of the hash table to prevent performance degradation.
- Resizing Process: The hash table is resized by creating a larger table and redistributing elements among the new slots. This process occurs when the average length of the linked lists exceeds a certain threshold.
Resizing Procedure:
- Threshold Check: The hash table monitors the average length of the linked lists.
- Resize Trigger: If the average length surpasses a set threshold, a new, larger hash table is created.
- Rehashing: All elements from the old hash table are rehashed and redistributed into the new hash table's slots.
- Performance Consideration: Resizing is resource-intensive but necessary to maintain hash table efficiency as the number of elements grows.
Advantages and disadvantages of Chained Hashing:
Advantages:
- Ease of Implementation: Chained hashing is relatively simple to implement.
- Adaptive Size: The hash table can dynamically adjust its size as needed.
- Good General Performance: Provides efficient performance for a wide array of applications.
disadvantages:
- Performance Degradation: Long linked lists can lead to reduced performance for specific applications.
- Expensive Resizing: The resizing operation, triggered by long lists, can be resource-intensive.
Chained hashing remains a popular choice due to its simplicity and adaptability, but its performance might suffer when dealing with extremely long linked lists, impacting specific types of applications.
EXAMPLE-1: Now let's consider an example of using Chained hashing to store the following data: 10, 22, 9, 4, 20, 7, 16, 28 and 5 in a hash table of size 3 using the modulo function.

- Initial Empty table

- Insert the first element 10 on hash table

- Insert the second element 22 on hash table, when collision occurs add to chain

- Insert the third element 9 on hash table

- Insert the fourth element 4 on hash table, when collision occur add to chain

- Insert the fifth element 20 on hash table

- Insert the sixth element 7 on hash table, when collision occur add to chain

- Insert the seventh element 16 on hash table, when collision occur add to chain

- Insert the eighth element 28 on hash table, when collision occur add to chain.

- Finally, insert the element 5 on hash table, when collision occur add to chain.

Chained hashing, when utilized for file organization, offers several advantages and drawbacks:
Advantages of Chained Hashing in File Organization:
- Efficient for Random and Even Data Distribution: Chained hashing excels in organizing large datasets within files, especially when data shows high randomness and even distribution throughout the file.
- Dynamic Hash Table Resizing: It allows dynamic resizing of the hash table, optimizing storage and retrieval operations within the file. This adaptability helps maintain efficiency as data volume changes.
- High Performance with Small Linked Lists: When the linked lists' average length remains small and the hash table isn't excessively large, chained hashing delivers commendable performance for file organization.
- Ease of Implementation with Standard Data Structures: Chained hashing can be implemented using standard data structures like arrays and linked lists, making it user-friendly and easy to incorporate into practical applications.
Disadvantages of Chained Hashing in File Organization:
- Inefficient Storage Utilization with Long Linked Lists: As the average length of the linked lists increases, especially in large files, chained hashing may lead to inefficient use of storage space.
- Costly Hash Table Resizing: Resizing the hash table, especially in large files with a high number of elements, can become an expensive operation, impacting system performance.
- Performance Issues with Certain File Structures: Chained hashing might not perform optimally for file structures requiring swift data search, complex query support, or fast retrieval compared to techniques like B-trees or indexing, especially in large files.
- Comparative Slowness: In comparison to other file organization methods like B-trees or indexing, especially in large files, chained hashing might exhibit slower performance.




{kind=link}
0 Comments