
Introduction
Ordered indexes within databases function akin to textbook indexes, providing efficient means to locate information within a dataset. They organize data in a structured manner, aiding in faster search and retrieval operations. These indexes, notably primary indexes, clustering indexes, and secondary indexes, provide to different database organization needs and offer varying levels of efficiency and functionality.
1. Primary Indexes
A primary index is an ordered file specifically designed for an ordered file of fixed-length records, comprising two fields: the primary key field's value and a pointer to a disk block. Each entry in the index corresponds to a block in the data file and contains the primary key field's value along with the pointer to the respective block. Primary indexes are sparse and facilitate faster data retrieval, employing binary search techniques, especially when the data file's ordering key field has unique values for each record.
Primary indexes excel in reducing block accesses during searches. However, they pose challenges during insertion and deletion operations, as reordering records impacts index entries and requires meticulous maintenance strategies.
Types of Primary Indexing:
A. Dense Index:

B. Sparse Index:

2. Clustering Indexes
In cases where file records are physically ordered based on a non-key field (clustering field), a clustering index comes into play. This type of index facilitates the retrieval of records sharing the same value for the clustering field. Unlike primary indexes, clustering indexes allow for multiple records to have identical values for the clustering field.
Clustering indexes maintain an ordered file with entries corresponding to distinct values of the clustering field and pointers to the first block containing records with the same clustering field value. While aiding retrieval efficiency, insertion and deletion of records in clustered files remain complex due to their physical ordering.
Example of Clustering Index:
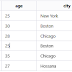
Imagine a database that stores details about various books, encompassing information such as their titles, authors, and publishers. Within this database structure, the title field stands out as a suitable candidate for the clustering field, enabling the grouping of books sharing identical titles.
To enhance the efficiency of searches based on book titles, a clustering index can be specifically devised and implemented on the title field. This index would encompass one entry for each block cluster within the data file. Each entry in this index contains the title of the initial book within the cluster and the corresponding block address, indicating the location of the block housing the book.
Whenever a search operation is initiated based on book titles, the clustering index becomes instrumental. It aids in quickly locating the block cluster that holds the books matching the specified title criterion, thereby speedup the retrieval process.

3. Secondary Indexes
Secondary indexes serve as additional means of accessing data files that already possess primary access structures. They can be created on non-key fields, either with unique values for every record or with duplicate values. Similar to primary indexes, secondary indexes are ordered files containing field values and pointers.
Dense secondary indexes include an entry for every record in the data file, while nondense ones might include multiple entries for the same field value, employing varied techniques like variable-length records or an extra level of indirection for efficient retrieval. Despite requiring more storage space, secondary indexes significantly enhance search time, especially for records inaccessible through primary indexing methods.
Understanding the nuances of these single-level ordered indexes empowers database practitioners to make informed choices aligning with specific database requirements, enhancing data retrieval efficiency, and optimizing database performance.
Advantages of Secondary Indexes:
- Improved Query Performance: Secondary indexes enhance query performance, especially for non-key fields, by enabling faster retrieval of specific data, optimizing search operations, and reducing query execution times.
- Faster Data Retrieval and Reduced Disk I/O: Utilizing secondary indexes leads to accelerated data retrieval, minimizing disk input/output (I/O) operations. This efficiency improves overall system performance during data access.
- Efficient Data Analysis and Decision-Making: Secondary indexes enable efficient analysis and decision-making processes by providing quick access to specific data subsets, facilitating better insights and informed decision-making within databases.
- Disadvantages of Secondary Indexes:
- Additional Storage Space Consumption: Maintaining secondary indexes requires additional storage space, contributing to increased storage overhead in databases compared to scenarios without secondary indexing.
- Impact on Database Performance during Updates: Index maintenance processes, especially during updates, insertions, or deletions, can potentially impact database performance, causing delays or inefficiencies in these operations.
- Complexity and Time-Consuming Management: The creation and management of secondary indexes can be complex and time-consuming tasks, demanding careful planning, implementation, and ongoing maintenance efforts, which might add to system complexities.

Advantages of Single Level Ordered Index:
- Faster Data Retrieval: Compared to scanning the entire table, single-level ordered indexes enable quicker retrieval of data by efficiently narrowing down search operations.
- Efficient Disk Space Utilization: As the index file is smaller in size compared to the data file, it optimizes disk space usage, contributing to better storage efficiency.
- Reduced Disk Access Times: The segregation of the index file from the data file results in reduced disk access times, enhancing overall system performance during data retrieval.
- Facilitates Range Searches and Sorting: Single-level ordered indexes provide a convenient mechanism for executing range searches and sorting operations, streamlining query executions.
Disadvantages of Single Level Ordered Index:
- Slower Update Processes: Updating the index file, especially when incorporating new data or removing old records, may take longer, potentially impacting the efficiency of data modification operations.
- Increased Disk Space Requirement: Maintaining an index file necessitates additional disk space, contributing to increased storage overhead compared to scenarios without an index.
- Maintenance Overhead: There's an inherent overhead associated with maintaining the index file, requiring resources and system processing for regular upkeep and management.



{kind=link}
0 Comments