
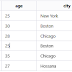
The hashing technique calculates storage block addresses for records on disk without relying on an index structure. Data is stored in data blocks with addresses generated by the hashing function. These locations are termed data buckets or blocks. The hash function, typically a complex mathematical formula, operates on specific columns (key or non-key) to obtain block addresses. Consequently, records are stored randomly, known as Direct or Random file organization. Using the primary key in the hash function commonly determines the data block's address, effectively making the primary key the block's address. This means rows with the same address as the primary key are stored in the same data block.
Retrieving records involves generating the address from the hash key column and directly retrieving the complete record without traversing the entire file. Similarly, inserting, updating, or deleting records involves generating the address via the hash key, enabling direct operations without searching or sorting the entire file. Each record is stored randomly in memory.
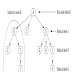
There are mainly two types of hashing techniques:



0 Comments